패스트 캠퍼스에서 수강하는 데이터 엔지니어링 강의 내용의 정리본이다.
Part1_Spotify_project
목차
- Step 1. 개요
- Step 2. 아티스트 관련 데이터 수집 프로세스
- Step 3. 데이터 분석 환경 구축
- Step 4. 서비스 관련 데이터 프로세스
Step 1. 개요
이번 강좌의 최종 목적은 음악 스트리밍 서비스인 spotify 에서 제공하는 음악, 아티스트 정보를 활용하여 특정 사용자가 음악이나 아티스트를 언급하면 해당 정보와 유사도가 높은 음악이나 아티스트를 제공하는 챗봇을 만드는 것이다.
- spotfiy : 사용자는 스포티파이를 이용하여, 메이저 음반사에서 라이선스한 음악을 스트리밍하여 들을 수 있는 서비스이다.
Step 2. 아티스트 관련 데이터 수집 프로세스
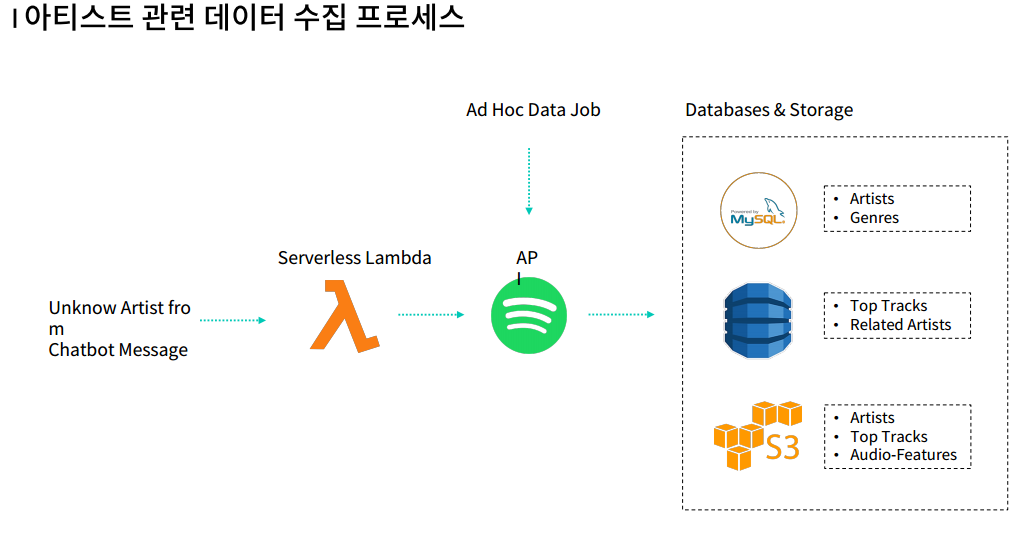
DB에 존재하지 않는 아티스트가 언급될 경우 Serverless Lambda가 trigger 역할을 하여 spotfiy의 API를 이용해 해당 아티스트에 대한 정보를 가져온다.
그 후 아티스트와 장르는 RDB인 MySQL, 탑 트랙과 관련 아티스트는 NoSQL인 Dynamodb, 그리고 Amazon S3를 이용해 아티스트, 탑 트랙 그리고 음악의 특징들을 저장한다.
각각의 DB들은 가지고 있는 성능과 특성이 다르다. 각각의 내용들은 추후에 다루도록 하겠다.
Step 3. 데이터 분석 환경 구축
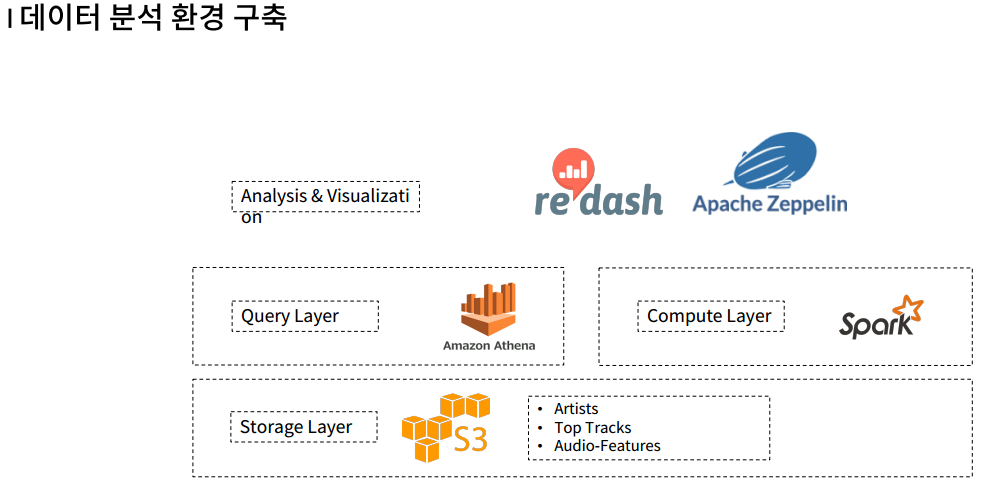
S3에 저장해 놓았던 데이터들을 기반으로 Amazon Athena와 Spark를 이용해 각각 필요한 분석들을 수행한다.
Amazon에 경우엔 Query를 이용해 다양한 분석을 실행하며 Spark에서는 블랙핑크의 노래가 어느 아티스트와 유사한지 계산하는 분석 등을 수행한다.
마지막으로 Apache Zeppelin 을 이용해 spark 환경에서 시각화 등 다양한 분석을 수행한다.
Step 4. 서비스 관련 데이터 프로세스
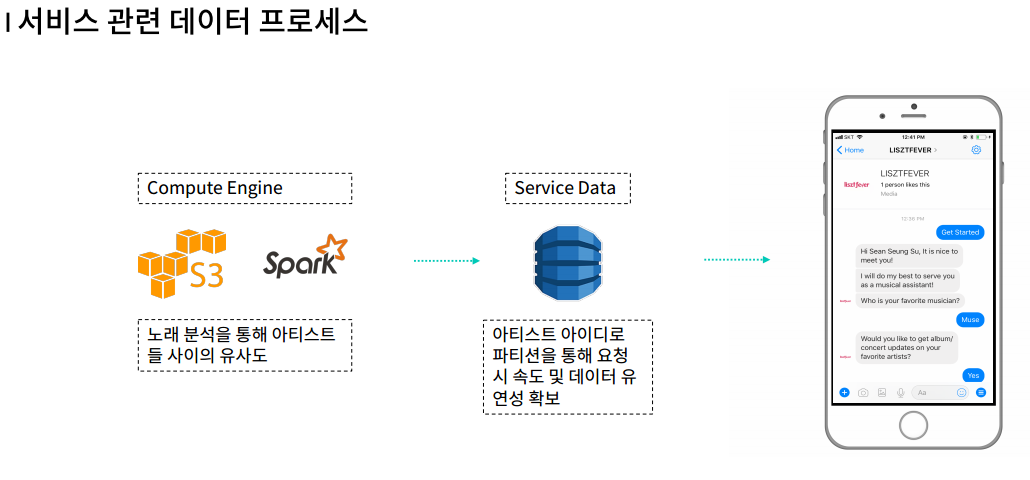
전체 개괄적인 서비스 프로세스이다.
1차적으로 아티스트와 해당 아티스트의 탑 트랙 노래들을 활용해 아티스트들 사이의 유사도를 계산한다.
그 계산된 데이터는 Dynamodb에 저장을 하게 된다. NoSQL DB를 사용하는 이유는 추후에 다루겠지만 들오는 데이터의 양과 형식이 매우 상이하기에 퍼포먼스의 목적을 위해 사용을 한다.
해당 DB에 저장된 데이터를 이용해 최종적으로 챗봇을 통해 서비스를 제공하게된다.